長いタイトルになりました。
今回は、JuliaのFluxを使ってニューラルネットワークを計算して、タイタニック号の生存者予測をしていきます。
Fluxを使ってみたかった、、ぐらいの話なので、精度はとか。。パラメーターは。。。とかはあまり突っ込まないでください。
参考にさせていただいたサイト等
Julia DataFrames – How to do one-hot encoding?
Juliaで機械学習:深層学習フレームワークFlux.jlを使ってみる その1:基本編
kaggleのtitanic ニューラルネットを使った生存者予測 [80.4%]
【Julia1.5】KaggleノートブックでJuliaを使用してタイタニック
実行環境
このソースは、以下の環境で実行しています。
- windows 11
- julia 1.8
- CSV v0.10.4
- DataFrames v1.3.4
- Flux v0.13.5
- MLDataUtils v0.5.4
- CategoricalArrays v0.10.6
タイタニックの生存者予測
タイタニックの生存者予測といえば、機械学習や統計の話では最初に取り掛かるような、Hello World的なものだと思います。
タイタニック号の性別や年齢、乗船の等級などを使って、生存したかどうかを予測するというもの。
Titanic – Machine Learning from Disaster
気になる方は、Kaggleを覗いてみてください。
使う条件
今回は、年齢(Age),性別(Sex),チケットクラス(Pclass),乗船料(Fare)の4項目を使います。
精度を上げるには、ほかの条件も使って、なんやらかんやらしたらとても精度が上がるそうですが、今回はFluxを使ってみるってのがテーマなのでこのぐらいで。
手順
どういう風に処理を進めていくか、整理しておきます。
- データ読み込みとクリーニング
- データの変換
- 学習
- 予測
今回はまだまだ、きれいなデータなので、クリーニングなんかは、そんなにゴリゴリしなくても大丈夫。本当ね汚いデータだと、クリーニングが結構大変よ。
では、実際一つ一つ進めていきましょう!
パッケージのインポートと環境設定
パッケージをインポートします。
using DataFrames,CSV,Flux,MLDataUtils,CategoricalArrays
using Statistics
using Flux:DataLoader
using Flux: @epochs, onehotbatch, onecold, logitcrossentropy, train!, throttle, flat
ENV["COLUMNS"]=1000
ENV["LINES"]=10DataFramesとCSVはデータ読み込みとデータ操作には不可欠なパッケージ。大体いつもセットで使ってます。
Statisticsは軽い統計計算をする標準パッケージの一つ。今回は使ってないけどStatsBaseはもっといろいろできます。データ分析するならStatsBaseも使う必要が出るかな。
Fluxは、Juliaの深層学習フレームワーク、今回のメイン。
ENV[“COLUMNS”]とENV[“LINES”]で、列と行の表示範囲を初期設定してます。列(columns)は全部見たいからいっぱい入れておけばいいかなと、行(lines)は、ふと、実行したときに30行もでたら見づらいから10行ぐらいにしてます。ここら辺は、お好みで設定してください
データ読み込みとクリーニング
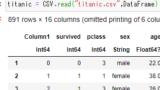
データはcsv形式のものがあるので、それをCSV.jlを使ってDataFrameとして読み込みます。
csvの読み込み方とDataFrameについてこちらの記事もどうぞ

データにはいくつか欠損値があるので、それをどうするか、決めます。
欠損値の扱いは、欠損値の行を消すとか、何か代替の情報で補完するとか、いくつか方法があります。
今回のデータだと、Age(年齢)に177件の欠損値があります。
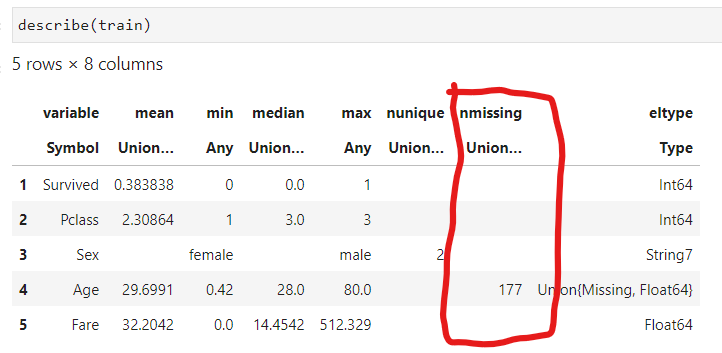
ちなみに予測するデータにはAge(年齢)とFare(料金)に欠損値があります。
今回は、いくつかの事例を参考に年齢中央値で埋めました。
ここまでのやり方は以下の通り
#データの読み込み
train_raw = CSV.read("train.csv",DataFrame);
test_raw = CSV.read("test.csv",DataFrame);
#データの選択
train =select(train_raw,:Survived,:Pclass,:Sex,:Age,:Fare);
#欠損値の補完
#年齢を中央値で補完
recode!(train[!,:Age], missing => median(skipmissing(train[!,:Age])));
train.Age = Array{Float64}(train.Age)
#料金を中央値で補完
recode!(train[!,:Fare], missing => median(skipmissing(train[!,:Fare])));
train.Fare = Array{Float64}(train.Fare)データの変換
ある程度きれいにしたデータを次は、学習させるためのデータに変換していきます。
データ変換では、以下の工程を進めていきます。
- ダミー変数の作成
- トレーニングデータとテストデータの分離
- 行列変換
ダミー変数の作成
例えば今は、性別はStringだしPclassも1から3なんだけど大きさに意味があるデータではなくて、カテゴリデータになってます。クラスが1・2・3でもA・B・Cでも表現の差みたいなもの?
性別とPclassをダミー変数に変換して使っていきます。
Juliaでダミー変数を作る方法はいくつかあるようなんですが、今回は次の方法でやっていきます。
ux = unique(tempdf.Sex);
transform!(tempdf, @. :Sex => ByRow(isequal(ux)) .=> Symbol(:sex_, ux));この投稿を参考に?というかほぼパクリですが。。。してます。
Julia DataFrames – How to do one-hot encoding?
いろいろ調べたんだけどもなかなかいいのがなくて。
FluxやLatheにもOnehotEncodingあったりOneHot.jlなんていうパッケージもあるんですけど、いまいちピンとこない感じ?
学習の後、予測用のデータでも同じように変換するので、取り急ぎ雑な関数にしておきます。
function getdummys(df)
tempdf = deepcopy(df)
ux = unique(tempdf.Sex);
transform!(tempdf, @. :Sex => ByRow(isequal(ux)) .=> Symbol(:sex_, ux));
ux = unique(tempdf.Pclass);
transform!(tempdf, @. :Pclass => ByRow(isequal(ux)) .=> Symbol(:pclass_, ux));
select!(tempdf,Not(:Sex))
select!(tempdf,Not(:Pclass))
endあとは、この関数を実行します。
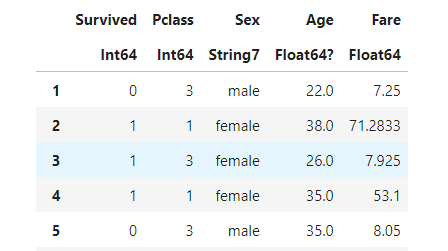
train = getdummys(train);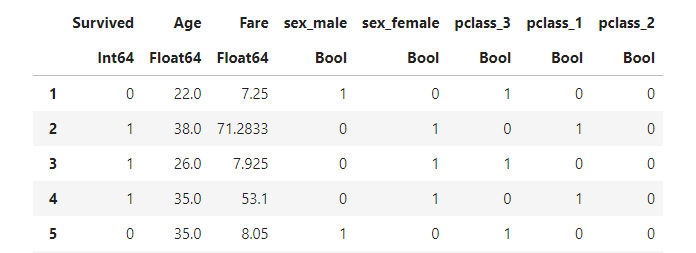
こんな風に「元の列名_カテゴリー名」に変換されます。
これで、ダミー変数化はOK!
トレーニングデータとテストデータの分離
ここまで出来たら、トレーニングデータとテストデータを分離します。
MLDataUtilsのstratifiedobsを使います。
(x_train,y_train),(x_test,y_test) = stratifiedobs((train,train.Survived), p=0.75)y_train,y_testはそれぞれの目的変数がベクトルで格納されます。
行列変換
ここまで来たら、ここから、ニューラルネットワークに入れていくためにDataFrame型のデータを行列に変換していきます。
今、トレーニングデータもテストデータも説明変数も目的変数も一緒に保管されてます。生存したかどうかのSurvivedとそれ以外の予測のための情報も一緒のDataFrameになってます。
まずは、それを分離します。
#トレーニングデータ
x_train = select(x_train,Not(:Survived));
#テストデータ
x_test = select(x_test,Not(:Survived));次にこれを説明変数は行列に変換します。
x_train = Matrix(x_train);
x_test = Matrix(x_test);これを実行すると、結果はこんな感じになります。
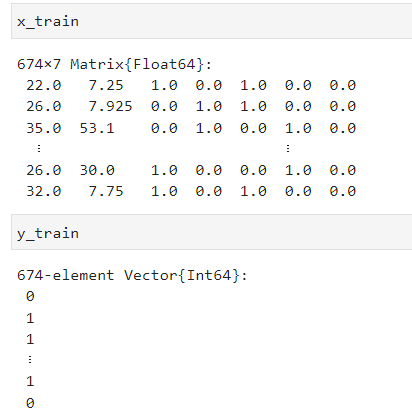
目的変数はこのままでOKですが、説明変数はこのままでは使えません。
ニューラルネットワークに入れるときにこのままだと674個の変数を入れていく?みたいになってしますので、これを転置します。
x_train = transpose(x_train);
x_test = transpose(x_test);この転置した行列をさらに変換します。Fluxで使う形に変換します。
x_train = Flux.flatten(x_train);
x_test = Flux.flatten(x_test);次に目的変数をFluxのOnehotを使って変換します。
y_train = Flux.onehotbatch(y_train,0:1);
y_test = Flux.onehotbatch(y_test,0:1);ちょっと説明雑ですが、これで、行列の変換は完了です。
もうちょっと勉強しないとだめね。うまく説明できない部分が多いです。
学習
データの準備ができたので、モデルを作って学習していきます。
レイヤーの作成
ニューラルネットワークのレイヤー作ります。
今回は入力が7、出力が2。入力層と中間層1層、出力層の3層から作りましょう。
今回はあくまで、やってみたい!の原動力なので、精度を上げたいとかこれがいい!とかではないです。(ただ、やってみたいだけ)
model = Chain(
Dense(7,5,relu),
Dense(5,3,relu),
Dense(3,2,sigmoid)
)Fluxでは、レイヤーの表現方法はいくつかあります。今回は、Denseっていう関数を使って層を表現して、Chainでつなぎます。
それぞれの活性化関数はreluと sigmoid。なんで?って聞かないでね。やってみたいだけだから。
学習の実行
FluxのDataLoaderを使って、ネットワークに入れるデータを読み込み損失関数や各種設定をして学習を実行します。
batch_size = 7
train_data = DataLoader((x_train,y_train);batchsize=batch_size,shuffle=true);
test_data = DataLoader((x_test,y_test);batchsize=batch_size,shuffle = true);
params = Flux.params(model)
optimiser = ADAM()
# loss(x,y) = logitcrossentropy(model(x), y)
loss(x,y) = Flux.binarycrossentropy(model(x),y)
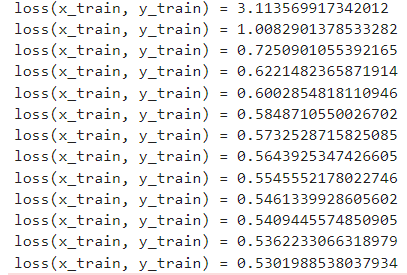
evalcb = () -> @show(loss(x_train, y_train))
epochs = 100
@epochs epochs train!(loss, params, train_data, optimiser, cb = throttle(evalcb, 5))今の環境だと一瞬で学習が終わります。
入力数が少ないしね。
正答率
一応正答率を見ておきましょう
function accuracy(data_loader, model)
acc_correct = 0
for (x, y) in data_loader
batch_size = size(x)[end]
# println(onecold(model(x)))
acc_correct += sum(onecold(model(x)) .== onecold(y)) / batch_size
end
return acc_correct / length(data_loader)
endこんな感じの関数を作って、正答率を計算します。
testmode!(model)
accuracy(test_data, model)まずは、学習モードからテストモードに変えて、テストデータをモデルにあててみます。
正答率は78%でした。
こんなもんでしょう?これで7割も当たってれば儲けもん?
予測
予測やっていきます。
まずは、予測に使うデータを学習に使ったデータのように変換します。
今回はtestという名前で処理してます。
test=select(test_raw,:Pclass,:Sex,:Age,:Fare);予測に使うデータには年齢と料金に欠損値があるので、それを埋めます。埋める条件は、学習データと同様にします(同様にしないとね、意味ないよね)
recode!(test[!,:Age], missing => median(skipmissing(test[!,:Age])));
test.Age = Array{Float64}(test.Age)
recode!(test[!,:Fare], missing =>median(skipmissing(test[!,:Age])));
test.Fare = Array{Float64}(test.Fare)予測データも学習データと同じ形にしていく必要があるので、性別とPclassについてダミー変数を作ります。
今回のダミー変数を作る雑な関数。作るときの条件によって、項目の順番が変わってしまうっていう致命的な欠点があるので、ダミー変数を作った後に学習データと並びが一緒になるように並び替えも行います。
test=getdummys(test);
select!(test,:Age,:Fare,:sex_male,:sex_female,:pclass_3,:pclass_1,:pclass_2);データができたら、これをニューラルネットワークに入れるために行列に変形していきます。
これは、学習データを作った時と同じ工程をします。
test = Matrix(test);
test = transpose(test);行列にして、それを転置して
もうちょっとカッコよく書くなら
test = Matrix(test)|>transposeパイプライン演算子を使ってこんな書き方もできる。
データの準備ができたので、学習したモデルに当てはめて予測してみます。
pred = onecold(model(test),0:1)onecoldをつかって、0,1の1列に変換してます。
一応これをKaggleにアップしてチェックしてみます。
そのために予測結果をSubmitのデータになるように整形します。その後それをcsvファイルに出力します。
submit= DataFrame(PassengerId = test_raw.PassengerId,Survived=pred)
CSV.write("submit.csv",submit)これで、KaggleにSubmitすれば、どんなもんなのかわかります。
スコアは内緒です。まぁ、学習したときの正答率ぐらいなのかな?
まとめ
今回はFluxをつかって、ニューラルネットワークを構築して、タイタニック号の生存者予測をしてみました。
データの前処理から始まって、データの整形、そして、モデル構築、学習。。といろいろな工程がありました。
モデルのパラメーターをいじって、正答率が上がった下がったなんていう遊びをするのもいいんですが、もし精度を上げていこうと思うと、データの準備が大切になります。
Kaggleのleaderboardなんて見てるとScore1.0とかあるし。。100%当たってるってことじゃんと思って
もしもっと気になることがあれば、参考にしたサイトを掲載してますので、そちらも見に行ってください。
おすすめ関連記事
CSVデータの読み込みや操作関係
CSV.jlの使い方やDataFrameの操作については、こちらの記事もあります。こちらもよろしくお願いします。


コメント