
前回は、JuliaでCSVファイルを読み込む3つの方法をご紹介しました。
今回は読み込んだデータを操作する方法について解説していきます。
juliaにはDataFrames.jlという、PythonでいうところPandasのようなものがあります。
ただ、DataFramesをよりよく使い、データを操作するときには便利なパッケージQuery.jlがあるので、それを使ってデータを操作してみましょう。
後半では、タイタニックのデータを使って実例をいくつか解説します
Query.jlでデータ自由自在
juliaにはquery.jlというSQLのような方法でdataframeを操作することができるパッケージがあります。
とっても便利なので、使っていきましょう。
気になる方は公式ページを見ると詳しく書いてあります。

Query.jlのインストール
Query.jlパッケージをインストールしていきましょう
Juliaのパッケージモードなら
(@v1.5) pkg> add QueryJupyterからインストールするなら
using Pkg
Pkg.add("Query")を実行してください。
チュートリアル
インストールできたので、どんなことができるのか少し使ってみましょう
df = DataFrame(name=["Takeshi","Kenji","Tomoe"],age=[54.,34.,23],children=[3,4,2])3×3 DataFrame
Row │ name age children
│ String Float64 Int64
────┼────────────────────────────
1 │ Takeshi 54.0 3
2 │ Kenji 34.0 4
3 │ Tomoe 23.0 2こんな感じでdataframeのデータがあったとします。
ここから、30歳以上の人を抽出して、名前だけのdataframeを作ってみましょう
パイプライン演算子を使って、どんどん入れ子にしていきます。
df|>
@filter(_.age>30)|>
@map({_.name})|>
DataFrameこういう風に書いて実行すると
2×1 DataFrame
Row │ name
│ String
─────┼─────────
1 │ Takeshi
2 │ KenjiDataFrame型の情報で出力されます
抽出したデータを新しいテーブルとして使いたいのなら
uppter30=df|>
@filter(_.age>30)|>
@map({_.name})|>
DataFrameという感じで、変数の代入のように使えばOKです。
TitanicのデータをQueryで操作してみる
実際のデータを使ってもう少しQuery.jlを使ってみましょう。
まずは準備から始めます。
タイタニックのデータはどこから持ってきてもOKです。
Kaggleでもいいし、seabornからDLしてもいいし、各種サイトから持ってきてもOKです。
準備:CSVファイルの読み込み
まずは、使うパッケージをインポートしておきましょう
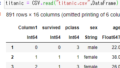
using CSV,DataFrames,Query次にCSVファイルの読み込み
titanic = CSV.File("titanic.csv")|>DataFrame必要な列を選んでデータづくり
今回は、見やすいように3つぐらい選びましょう
生死(survived)、性別(sex)、年齢(age)のデータを持ってきてdfを作ります。
df = titanic|>
@map({_.survived,_.sex,_.age})|>
DataFrameこれでまずはdfが出来上がりました。
891×3 DataFrame
Row │ survived sex age
│ Int64 String Float64?
─────┼─────────────────────────────
1 │ 0 male 22.0
2 │ 1 female 38.0
3 │ 1 female 26.0
4 │ 1 female 35.0
5 │ 0 male 35.0
6 │ 0 male missing
7 │ 0 male 54.0
8 │ 0 male 2.0
9 │ 1 female 27.0
10 │ 1 female 14.0
11 │ 1 female 4.0
⋮ │ ⋮ ⋮ ⋮
882 │ 0 male 33.0
883 │ 0 female 22.0
884 │ 0 male 28.0
885 │ 0 male 25.0
886 │ 0 female 39.0
887 │ 0 male 27.0
888 │ 1 female 19.0
889 │ 0 female missing
890 │ 1 male 26.0
891 │ 0 male 32.0
870 rows omittedこれからこれを操作していきます。
ここで気を付けたいのは最後にちゃんとDataFrameに渡さないとDataFrameにならないので注意してください。
|> DataFrameを忘れずに
欠損値(missing)を消す
データには欠損値(missing)があるものなので、ここでは欠損値を削除しましょう。
欠損値をどういう扱いするかは、その時によって様々でしょうけど、今回は削除です。
Query.jlには@dropnaっていう便利なマクロがあるので、それ使います。
今回のデータには年齢(age)に欠損値があるので、それをドロップします。
df = df |>
@dropna(:age)|>
DataFrame@dropna(列名)っとやることでその列の欠損値を削除できます。
実行結果はこんな感じ
714×3 DataFrame
Row │ survived sex age
│ Int64 String Float64
─────┼───────────────────────────
1 │ 0 male 22.0
2 │ 1 female 38.0
3 │ 1 female 26.0
4 │ 1 female 35.0
5 │ 0 male 35.0
6 │ 0 male 54.0
7 │ 0 male 2.0
8 │ 1 female 27.0
9 │ 1 female 14.0
10 │ 1 female 4.0
11 │ 1 female 58.0
⋮ │ ⋮ ⋮ ⋮
705 │ 1 female 25.0
706 │ 0 male 33.0
707 │ 0 female 22.0
708 │ 0 male 28.0
709 │ 0 male 25.0
710 │ 0 female 39.0
711 │ 0 male 27.0
712 │ 1 female 19.0
713 │ 1 male 26.0
714 │ 0 male 32.0
693 rows omitted元々891行あったのが714行になりましたね。
177件の欠損値があったようですね。
データを色々眺めてみる
ここから、データを色々眺めてみながら、Query.jlの使い方を見てみましょう
まずはQuery.jlの機能ではなく、DataFramesの機能を使って少しデータを見ます。
describe(df)でデータの様子を見ましょう。
describe(df)
3×7 DataFrame
Row │ variable mean min median max nmissing eltype
│ Symbol Union… Any Union… Any Int64 DataType
─────┼──────────────────────────────────────────────────────────────
1 │ survived 0.406162 0 0.0 1 0 Int64
2 │ sex female male 0 String
3 │ age 29.6991 0.42 28.0 80.0 0 Float64生存者を抽出する
生き残った人の数を少し見てみましょう
survivedが1が生存0が死亡です
df|>
@filter(_.survived == 1)|>
DataFrame
290×3 DataFrame
Row │ survived sex age
│ Int64 String Float64
─────┼───────────────────────────
1 │ 1 female 38.0
2 │ 1 female 26.0
3 │ 1 female 35.0
4 │ 1 female 27.0
5 │ 1 female 14.0
6 │ 1 female 4.0
7 │ 1 female 58.0
8 │ 1 female 55.0
9 │ 1 male 34.0
10 │ 1 female 15.0
11 │ 1 male 28.0
⋮ │ ⋮ ⋮ ⋮
281 │ 1 female 42.0
282 │ 1 female 27.0
283 │ 1 male 4.0
284 │ 1 female 47.0
285 │ 1 female 28.0
286 │ 1 female 15.0
287 │ 1 female 56.0
288 │ 1 female 25.0
289 │ 1 female 19.0
290 │ 1 male 26.0
269 rows omitted290人が生存したようですね。
男女の生存者数を集計する
男女のそれぞれの生存数を見てみましょう
ここで使うのが@groupbyというやつ。集計できるわけですね。
df|>
@filter(_.survived ==1)|>
@groupby(_.sex)|>
@map({Key=key(_),Count=length(_)})|>
DataFrame
2×2 DataFrame
Row │ Key Count
│ String Int64
─────┼───────────────
1 │ female 197
2 │ male 93女性が197人、男性が93人だったようです。
まとめ
今回はQuery.jlを使ってみました。
もっともっと使い方は色々あるんですが、こんなことができるよーぐらいの紹介にはなったでしょうか?
Query.jlを使うと、SQLのクエリ操作のようにdataを色々と操作できます。
今回は紹介していませんがQuery.jlではLINQ Styleの使い方もできます。
大きいデータの並べ替えや列の抽出や集計などなど、便利で使いやすいので、体験してみるのもいいかもしれません。
ではまた!

コメント
[…] Query.jlについては、juliaのDataFramesとQueryでデータを操作するで解説しています。気になる方はそちらをご覧ください […]