Juliaでクラスタ分析をやってみようっていう話です。
今回はK-means(K平均法)やってみます。教師なし学習っていうやつですね。
さて、Juliaでクラスター分析するときに使えるパッケージがあります。その名も「Clustering.jl」そのまんまの名前です。
チュートリアルにあるIrisのK-meansやっていきましょう。
パッケージのインストール
まずはパッケージのインストールから
REPL環境であればパッケージモードから、
(@v1.7) pkg>add Clusteringjupyter-notebookなどからインストールするなら
using Pkg
Pkg.add("Clustering")K-meansやっていこう!
パッケージの準備ができたので、実際にK-means(K平均法)やっていきましょう
データセットをRDatasetsから持ってくる方法とMLDatasetsから持ってくる方法、両方を紹介します。
データの準備-RDatasetsを使う場合-
まずはRDatasetsからやっていきましょう
using RDatasets
iris = dataset("datasets","iris");
features = collect(Matrix(iris[:,1:4])');Irisのデータセットを持ってきて、それを整形します。
Matrix(iris[:,1:4])'最後につけてるシングルクオーテーションは、転置行列を求めてます。K-meansで使う形に変えているってことですね。
これしないと、求めるものが出てきません。
データの準備-MLDatasetsを使う場合-
次にMLDatasets
using MLDatasets
features = Iris.features();
MLDatasetsの場合は、整形されてるので、DLしてくるだけでOK.
クラスタリングとプロット
データが準備できたので、K-meansでクラスタリングしてきましょう。
result = kmeans(features,3);これでクラスタリングが完了します。
では、プロットしていきましょう
RDatasetsの場合
using Plots
scatter(iris.PetalLength,iris.PetalWidth,markercolor=result.assignments,color=:lightrainbow,legend=false)MLDatasetsの場合
scatter(iris[3,:],iris[4,:],markercolor=result.assignments,color=:lightrainbow,legend=false)RDatasetsの場合だと、データがDataFrameで作ってあって、MLDatasetsだと行列で作ってあります。
RDatasetsであれば、ラベルで指定できるけど、MLDatasetsの場合は、行列の形式で指定する。
プロットするとこんな感じで、きれいにクラスタリングできますね。
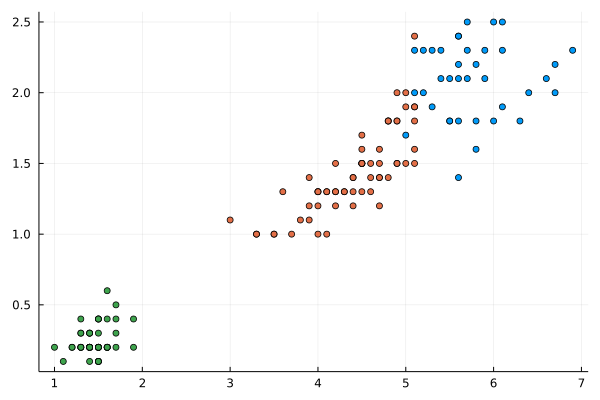
まとめ
今回はJuliaのパッケージ”Clustering.jl”を使ってクラスター分析(K-means)をやってみました。
データセットの用意の方法も2通りご紹介しました。
RDatasetsはRのデータセットを使えるようにするパッケージで、1000を超えるデータセットがあるので、気になる人はチェックしてみてもいいと思います。
ではまた

コメント