
今回はjuliaを使って1変量の基本的な統計量と軽くグラフをやっていきます。
パッケージの導入と実行環境
- MacOS 26.0
- julia 1.12.1
- DataFrames v1.8.1
- RDatasets v0.7.7
- StatsBase v0.34.7
- StatsPlots v0.15.8
データの準備
今回使うデータは、Davisの身長と体重がはいってるやつ。
df = dataset("car","Davis");どんなデータか、最初の5行ほど見てみましょう
first(df,5)
5×5 DataFrame
Row │ Sex Weight Height RepWt RepHt
│ Cat… Int32 Int32 Int32? Int32?
─────┼──────────────────────────────────────
1 │ M 77 182 77 180
2 │ F 58 161 51 159
3 │ F 53 161 54 158
4 │ M 68 177 70 175
5 │ F 59 157 59 155
summary()とdescribe()で、データの外観を観察。
summary(df)
"200×5 DataFrame"
describe(df)
5×7 DataFrame
Row │ variable mean min median max nmissing eltype ⋯
│ Symbol Union… Any Union… Any Int64 Type ⋯
─────┼──────────────────────────────────────────────────────────────────────────
1 │ Sex F M 0 CategoricalValue{String, ⋯
2 │ Weight 65.8 39 63.0 166 0 Int32
3 │ Height 170.02 57 169.5 197 0 Int32
4 │ RepWt 65.623 41 63.0 124 17 Union{Missing, Int32}
5 │ RepHt 168.497 148 168.0 200 17 Union{Missing, Int32} ⋯
1 column omitted
欠損値があったり、体重の最大値が166キロかな?ちょっと、外れ値っぽいのもあるかもね。
それも踏まえてやっていきましょう。
基本統計量
今回は、身長(height)を使ってやっていきます。
身長のデータだけ取り出しておきましょう
height = df.Height;代表値
最小値や最大値、平均値など、データを表す代表的な値
最小値
minimum(height)
57最大値
maximum(height)
197中央値
median(height)
169.5平均値
mean(height)
170.02最頻値
mode(height)
178
modes(height)
1-element Vector{Int32}:
178最頻値が2つ以上ある場合は、modes()を使うことで、ベクトル値で値が返ってくるよ
四分位数
quantile(height)
5-element Vector{Float64}:
57.0
164.0
169.5
177.25
197.0分布の様子
散らばり加減やどんな分布なのかを表してる
範囲
maximum(height)-minimum(height)
140分散
var(height)
144.19055276381906標準偏差
std(height)
12.00793707361173歪度
skewness(height)
-4.034723962975985尖度
kurtosis(height)
37.47093496530418基本的なグラフ
グラフを作図して、特徴を視覚的にもとらえましょう。
棒グラフ
bar(height)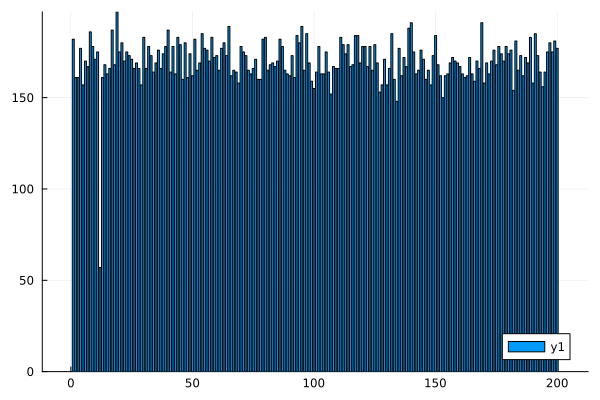
ヒストグラム
histogram(height)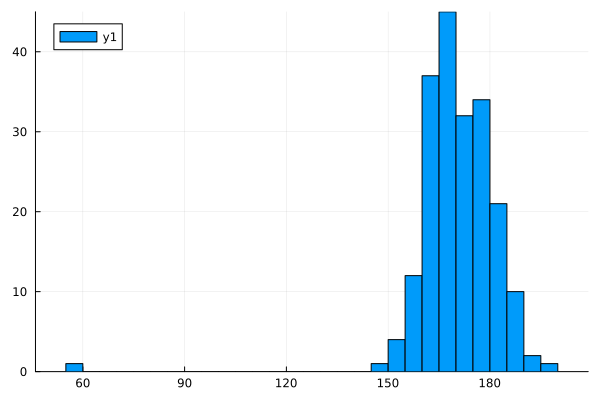
密度グラフ
density(height)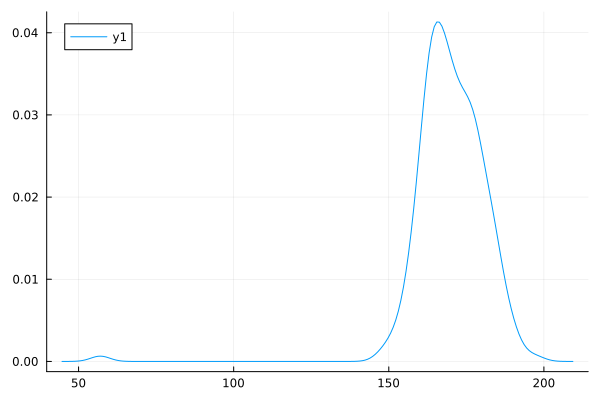
ボックスプロット
boxplot(height)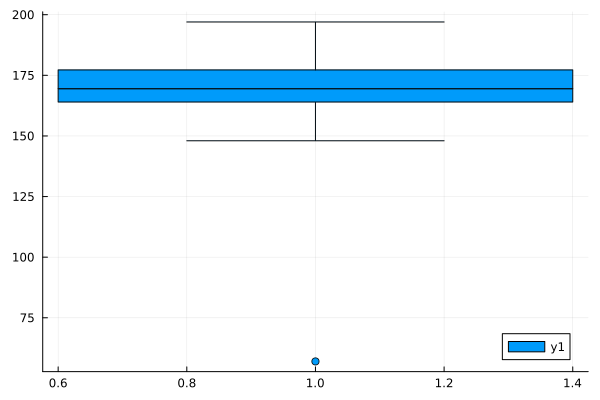
ドットプロット
dotplot(height)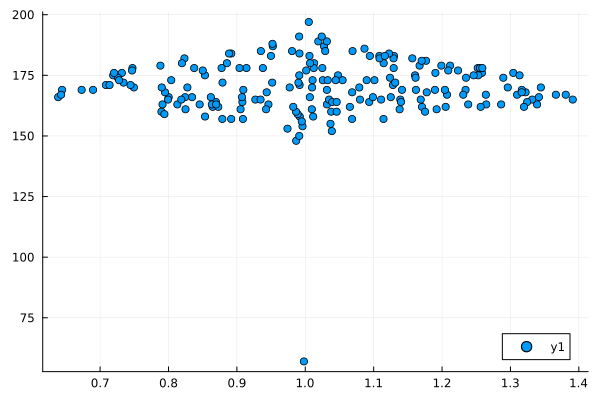
まとめ
ざーっと、基本的なのをずらずらっとだしました。みるからに外れ値っぽいのがあるよね。
身長のデータなのに最小値が57センチって。赤ちゃん?それをもう少し観察するには、これのセットになってる体重のデータも見てみないとわからないね。
2変量以上のものについても、今後、まとめていきます。相関係数とか散布図とかそういうのだね。
おたのしみにー

コメント