juliaでグラフを描画する方法を解説してきます。
今回は応用編1です
CSVやDataFramesなどを使ってタイタニックのデータを加工して、グラフに描画していきましょう
Plotsのパッケージのインストールやインポートの方法はJuliaでグラフをプロットする-基礎編-
をご覧ください
グラフの見た目を加工する応用編はこちら>>Juliaでグラフをプロットする‐応用編2‐
CSVはJuliaでCSVファイルを読み込む3つの方法-Julia1.8対応-
時系列データのグラフはjuliaで時系列-その2-時系列データのグラフ描画をご覧ください
実行環境
このソースは、以下の環境で実行しています。
- windows 11
- julia 1.8
- CSV 0.10.4
- DataFrames 1.3.4
- StatsPlots 0.15.1
- StatsBase 0.33.21
タイタニックのデータを読み込む
前回の基礎編では、単純なランダムデータを使ったりしました。今回はタイタニックの生存者データを使いながらいろいろなグラフを見ていきます。
では、まずは、データの読み込みをしましょう
train = CSV.read("train.csv",DataFrame);csvデータを読み込みます。
データの中身も少し見てみましょう
first(train,10)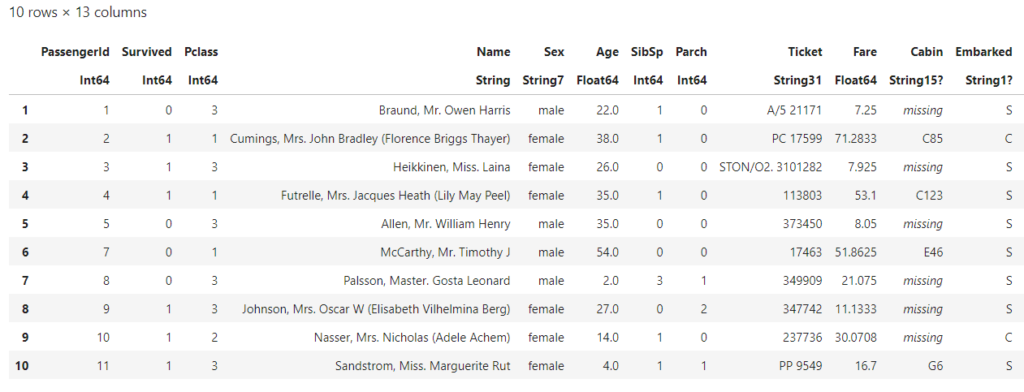
describe(train)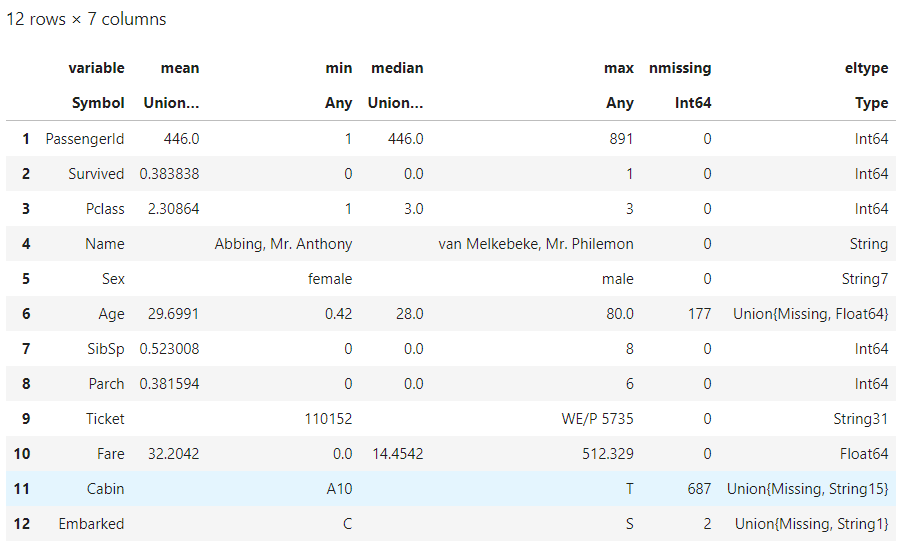
よくあるタイタニックのデータですね。
データの加工
今回は、そんな厳密に分析するわけではないので、使いやすいように軽くデータを加工します。
今回は、Survived,Age,Sex,Fareを使って、グラフを描画していきます。
欠損値処理
まずは、欠損値を処理します。
Ageに少し欠損値がみられるので、それを削除します。
train = dropmissing(train,:Age);カテゴリーデータの処理
次にSex(性別)の部分。
グラフによっては、文字列が使えないものもあるので、数字に置き換えます。
文字列が使えるものでは、それも使いたいので、文字列バージョンはそのままで、数字に置き換えたものは小文字のsexにしておきましょう
f(x) = x=="male" ? 0 : 1
transform!(train, @. :Sex => (x -> f.(x))=>:sex);male(男性)が0で女性が1に変換されます。
データのグループ化
次にグループ化を行います。
生存者グループと死亡グループに分けて、サブテーブル作ります。
gd = groupby(train,:Survived);
これで、データの加工は完了です。
StatsPlotsを使います。
今回は、StatsPlotsというPlotsの拡張?を使ってグラフを描画していきます。
StatsPlotsを使うと、DataFrameのデータを描画したり、今回つかう、バイオリンプロットやボックスプロットなんかができるようになります。その名の通り統計的なデータ描画に強くなれるわけです。
さらにStatsPlotsはデータフレームをサーポートしてます。
データフレームのデータを描画する場合
Plotsの場合だと
plot(df.xx)というようにデータフレーム名とカラム名を指定してグラフを描いてました
StatsPlotsを使うと
@df df plot(:XX)このように データをカラム名だけで渡せるようになります。
カラムが一つだけなら、あまり利便性を感じませんが
@df df plot(:xx,:yy,....)とカラムが増えたりすると、途端に便利になります。
では、始めましょう!
タイタニックのデータを様々にプロットしてみる。
準備が完了したので、いろいろなグラフでプロットしていきます。
年齢についてヒストグラムを描いてみる
まずは、ヒストグラムを使って、年齢の分布を見てみましょう
histogram(x)
まずは、全体の様子を見ます。
0歳から100歳まで、刻みを10歳刻みにします。
@df train histogram(:Age,bins = 0:10:100,title = "All age")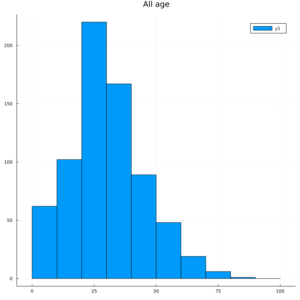
平均年齢が29.6歳ぐらいなので、そのあたりに線を引いてみましょう
vline!([Int(floor(mean(train.Age)))],linewidth = 4)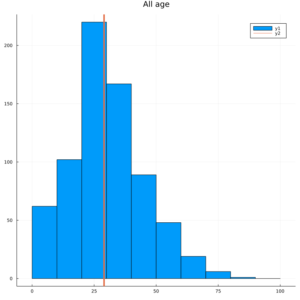
vline!([x])”!”付きで実行することで、後から、グラフに追加できます。
グループ化したタブテーブルを使って、生存者と死亡者の年齢の様子も見てみましょう。
まずは、生存者から
@df gd[(Survived = 1,)] histogram(:Age,bins=0:10:100,title = "Survived")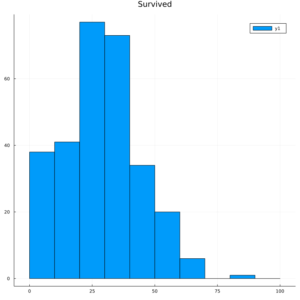
そして、死亡者
@df gd[(Survived = 0,)] histogram(:Age,bins=0:10:100,title = "Dead")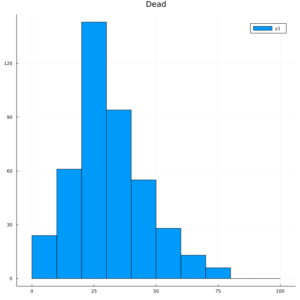
グループ化すると、それぞれのグループを指定できます。
gd[(Survived = 0,)] こういうようにキーによって、選択することもできますし
gd[1] テーブルの中を直接選択することもできます。
ヒストグラムを見てみると、生存者は、年齢の低い方がに偏っている傾向があるようですね。
やはり、子供を助けようとしたのでしょうか?そんなことが見えてきます。
運賃についてボックスプロットを描いてみる
次に、運賃(Fare)を軸に見てみましょう。
今回はボックスプロットを使ってみます。
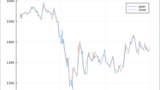
@df train boxplot(:Survived,:Fare)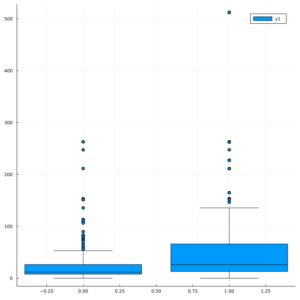
これは、SurvivedとFareをボックスプロットで見てた様子です。
左側が死亡。右側が生存です。
運賃が高い方が、どうも生存している人が多いような?感じがしますね。右側(生存)の上の方にものすごい高い値があります。
もう少し詳しく見るにはほかのグラフを描いてみたり計算してみるといいと思います。
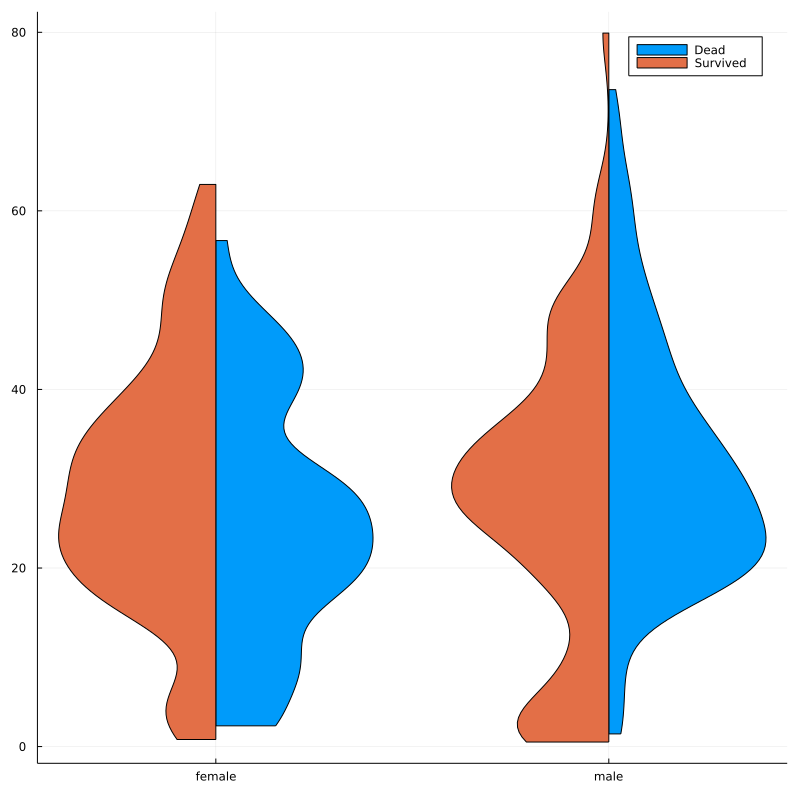
性別・年齢・生存について、バイオリンプロットを描く
次にバイオリンプロットを使っていきましょう。
@df gd[(Survived = 0,)] violin(:Sex,:Age,side=:right,label="Dead")
@df gd[(Survived = 1,)] violin!(:Sex,:Age,side=:left,label="Survived")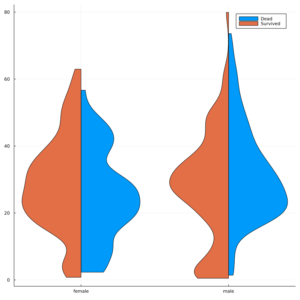
オレンジ色が生存、青色が死亡です。横軸は、女性・男性、縦軸は年齢です
パット見た印象ですが、男性についていうと、死亡した方は、年齢が整った分布をしてますが、生存者は、偏りを感じます。逆に女性についていうと、生存者は、少し偏りがあるものの、そこ満遍なく多くの年代の方が助かったのかなという印象です。
最初のヒストグラムで見たときに、生存者は若年層側に偏りがあったことを踏まえると、女性と子供をまずは守ろうとしたのかなという印象があります。
性別・年齢・生存について、ドットプロットを描く
次にドットプロットを描いていきます。
@df gd[(Survived = 0,)] dotplot(:Sex,:Age,label="Dead",markersize = 10)
@df gd[(Survived = 1,)] dotplot!(:Sex,:Age,label="Survived",markersize = 10)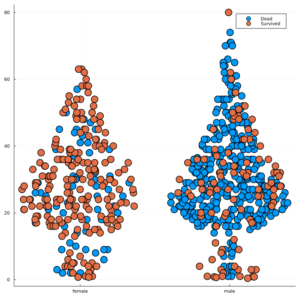
ドットプロットはバイオリンプロットと同じようなつくりです。
バイオリンプロットが密度関数みたいなものですが、ドットプロットはデータをそれぞれとっています。
先ほどのバイオリンプロットと同じで、オレンジが生存・青が死亡です。横軸の左側が女性・右側が男性です。
ぱっと見の印象はどうでしょうか?
明らかに女性の方が生存率が高そうですね。
まとめ
今回は、タイタニックのデータを使って、いくつかのグラフを描いてみました。
分析をしようと思うともっといろいろしっかり見ていかないといけませんが、最初に「どういうデータなのかな?」と思ってみるには、これらのグラフが役に立つんじゃないかと思います。
ヒストグラムは、階級の取り方で、印象も変わってきます。10歳刻みだと、なんだか、整っているように見たものも、例えば、年齢を10歳刻みではなく5歳刻みにすると
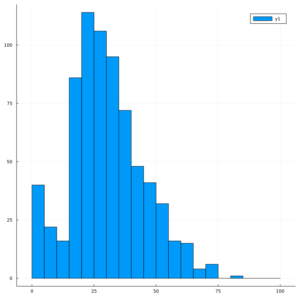
こんな感じになって、「0歳あたりが多いなー、偏りがあるなー」みたいな印象になると思います。
ほかのグラフもどういう風にデータを使うかで印象ががらりと変わります。
応用編2では、もう少し違うグラフについても扱っていきたいともいます。


コメント