juliaで時系列分析を行っていきます。
今回は、株式のデータを扱っていきます。
証券会社からダウンロードしたCSVデータをjuliaの時系列分析で使う形式に変換するのが今回の目標です。
ではやっていきましょう!
必要パッケージのインストール
必要になるパッケージは次の通りです
- Dates.jl
- TimeSeries.jl
- CSV.jl
- DataFrames.jl
上の2つが時系列に係ること、下の二つがデータ操作に係るパッケージです。
それぞれインストールしていきましょう。
REPL環境であればパッケージモードから、
(@v1.7) pkg>add Datesjupyter-notebookなどからインストールするなら
using Pkg
Pkg.add("Dates")こんな風にして、それぞれ4つインストールします。
CSVファイルの読み込みと加工
準備ができたところで、CSVファイルを読み込んで、時系列分析で扱う形式に変えてきましょう。
juliaでテーブルデータを扱うときには、DataFrame型を使うことが多いです。時系列で扱うときには、TimeArray型があります。
今回はCSVを一度DataFrameに変換して、その後、TimeArrayにしていこうと思います。
(それぞれ、データを処理するときに一長一短があります。)
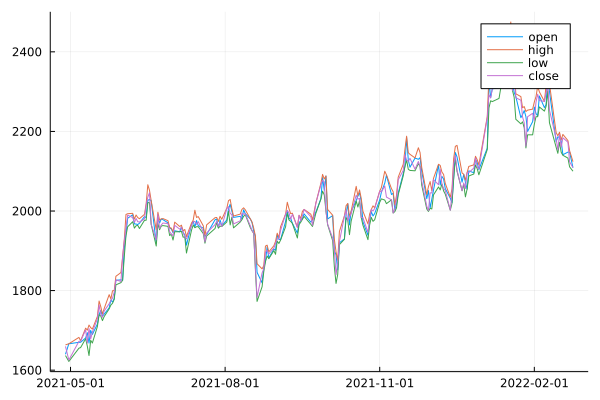
今回は、松井証券からデータをダウンロードしてきて使います。
証券会社やFX業者など、それぞれの会社によって、データの種類や形式が少し違います。
今回は不必要な部分を削って、株価データでよく使う「ohlc」の並びにしていきます。
CSVデータの読み込み
まずは、松井証券からデータを持ってきます。(お使いの環境で手に入れやすいデータを探してください)
今回は世界のトヨタの株価データ持ってきました。

松井証券からCSV出力でデータを持ってくると、
銘柄コード、銘柄名、市場、日付、時刻、始値、高値、安値、終値、出来高、移動平均5,移動平均20、移動平均60、RSI
といった具合に色んなデータが盛り込まれて、出力されます。
今回はこれをOHLC(始値、高値、安値、終値)の並びのデータに加工してきます。
では始めます!
ファイル名を”toyota.csv”にしましょう
using CSV,DataFrames
data = CSV.read("toyota.csv",DataFrame)これで、dataにトヨタの株価データが入ってきます。
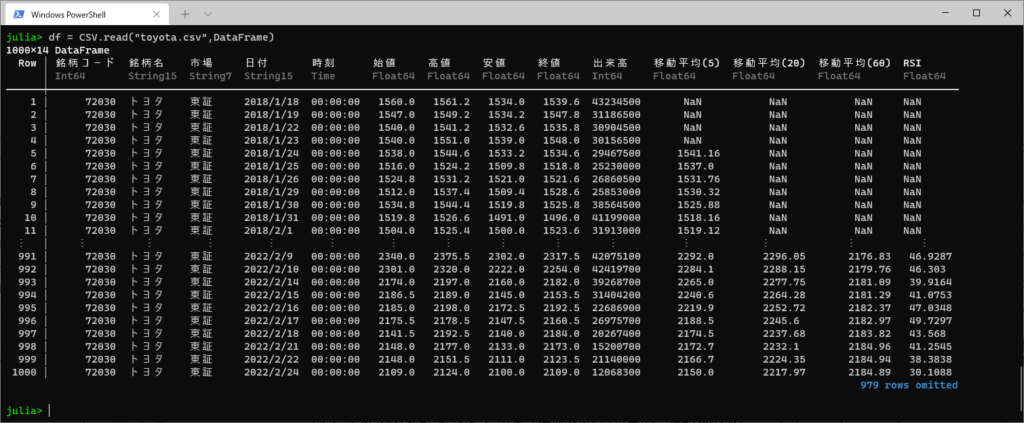
読み込むとこんな感じです。
もし表示したくない場合は
data = CSV.read("toyota.csv",DataFrame);最後に「;」セミコロンをつければ表示されません。
データの加工-いらないものを消す-
さて、今回必要なデータは、OHLCを作るための「日時・始値・高値・安値・終値」です。
まずは、いらないデータを消して、ほしいデータのみにします。
dataframeでは、ほしいものを選んで、並べれば、その通りに並んでくれます。
ほしい列は、
- 4ー日時
- 6-始値
- 7-高値
- 8-安値
- 9-終値
です。
df=df[!,[4,6,7,8,9]]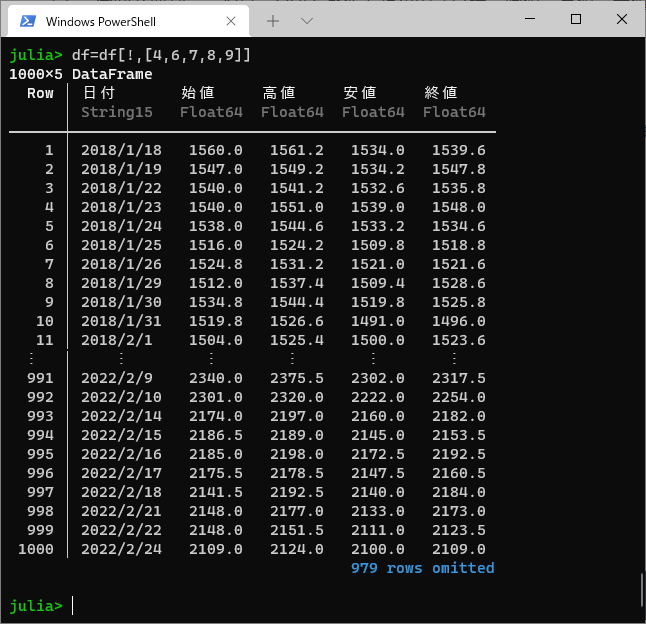
必要なデータが出てきました。
今後の処理のために列の名前を日本語から英語に変えてきましょう。
rename!(df,[:date,:open,:high,:low,:close])これで、必要なものだけ取り出せました。
データ加工-日付処理と時系列データへ-
では、dataframe型のデータを時系列を使うためのTimeArray型に変換してきます。
ここでは、DatesパッケージとTimeSeriesパッケージを使います。
ではもう一度、今作ったデータを見てみます。
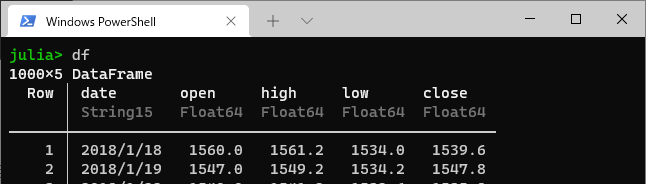
dateの列のデータ型が、Stringになってます。
これは、文字列であって、日時データではないので、これを日時データに作り替えます。
例として、1行1列目の文字列「2018/1/18」を日付のデータに変えてみます。
julia> Date(df[1,1],dateformat"y/m/d")
2018-01-18こんな風に変わります。
julia> typeof(Date(df[1,1],dateformat"y/m/d"))
Dateタイプを見るとDate型になってます。
これを全部に適用します。
全部に適用するときは「.(ドット)演算子」を使います。
df.date = Date.(df[!,1],dateformat"y/m/d")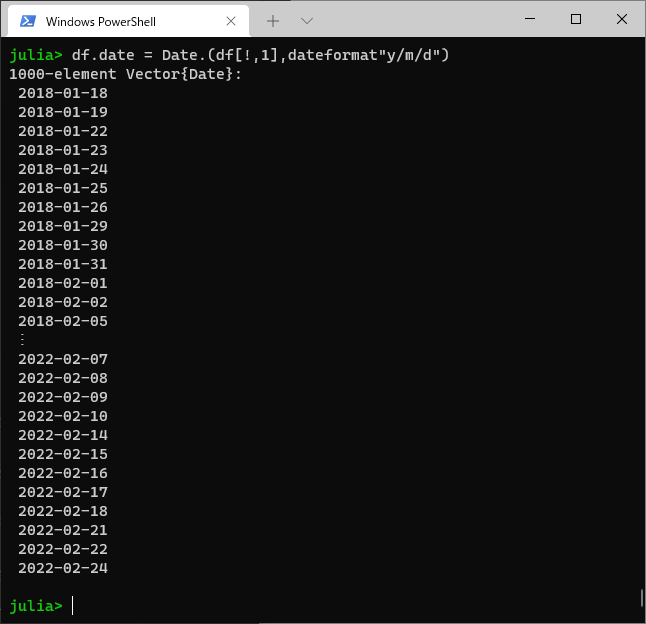
これで、もう一度dataframeを見てみましょう
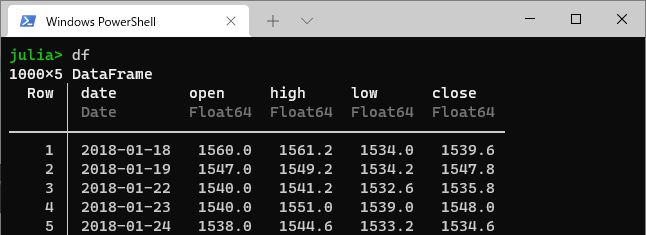
ちゃんとデータ型がDateになってますね。
ここまで来たらあとは簡単です。
これをTimeArray型に変更します。
ta=TimeArray(df,timestamp = :date)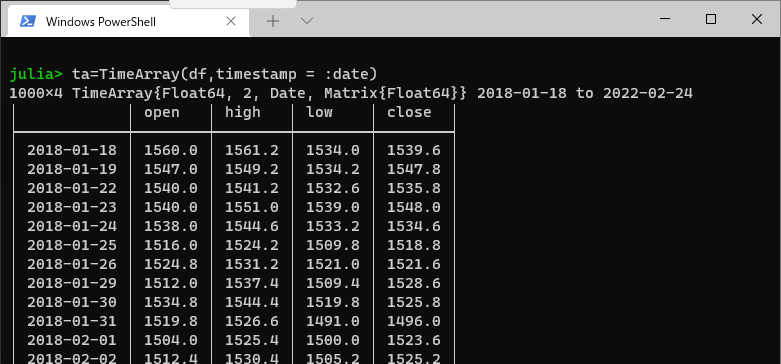
無事、TimeArrayにできましたね。
引数のtimestampは日付型のデータを渡します。
先ほど文字列を日付に直したので、その列を指定します。
もし変更せずにこの処理を行うとエラーが出力されます。
処理を関数化する
ここまでの一連の処理を自動化するために関数化しちゃいましょう。
関数化といっても一連の処理をまとめるだけです。
関数化するとこんな感じです。
function csv2ohlc(filename)
df = CSV.read(filename,DataFrame)
df= df[!,[4,6,7,8,9]]
DataFrames.rename!(ohlc,[:date,:open,:high,:low,:close])
df.date = Date.(df[!,1],dateformat"y/m/d")
TimeArray(df,timestamp = :date)
endこれで完成です。
色んな会社のCSVファイルからOHLC並びのデータを作ることができます。
まとめ
データの読み込みから、不要データの削除、データ型の変換などの加工を経て、目的のデータを創り出せました。
そして、自動化のために最後は関数化することも試みました。
最後TimeArray型まで一気に変換する関数にしましたが、使い勝手を考えて、CSVからdataframeに変換して加工するまでの工程だけの関数を作るのもひとつかもしれませんね。
変わらない一連の作業は、関数化して楽しちゃいましょう
次回は、移動平均とかを扱っていきます。

コメント